简介
Bloom Filter是由 Burton Howard Bloom在1970提出的,用来判断一个元素是否存在集合中的概率算法。经过Bloom Filter判断过不在集合中的元素就一定不在集合中,若判断结果是在集合中,则可能会误判,即该元素可能不在集合中。换句话说,可能会误判,但绝不可能漏判。元素可以添加到集合中,但不会被删除(尽管可以通过“计数”过滤器来解决); 添加到集合中的元素越多,误判的概率就越大。Bloom Filter将元素映射到位数组中,所以极大的节省空间。
算法描述
通常我们判断一个元素是否在集合中,可以将集合存放在一个列表等数据结构中,通过比对查找的方式判断是否包含该元素,但是当元素的个数越来越大时,列表占用的内存空间会越来越大,可以将其存放在磁盘空间中,但是这样会大大降低查询时间。进一步改进,可以通过散列表来映射元素到二进制位数组中,真正的数据存放磁盘空间中,内存存放散列表,通过元素散列映射的位是否为1判断元素是否存在集合中。但是散列表当元素增加时,发生冲突的概率也不断增大,冲突会降低查询的效率,为了减少冲突,可以通过多个哈希函数解决,当一个元素通过多个哈希函数映射的位都为1时,那么判断元素可能在集合中,否则元素必定不在元素中。Bloom Filter就是使用这种方法。
初始化
Bloom Filter是通过不同的哈希函数映射到位数组,初始化是一个位数组,数组元素全设置为0,代表目前没有元素在集合中,数组的初始化长度下文会介绍。

插入元素
插入的元素需要通过k个哈希函数得到k个对应的位数组上的位置,将这些位置上的位全都设置为1,若已经设置为1,则可以不做任何改变。
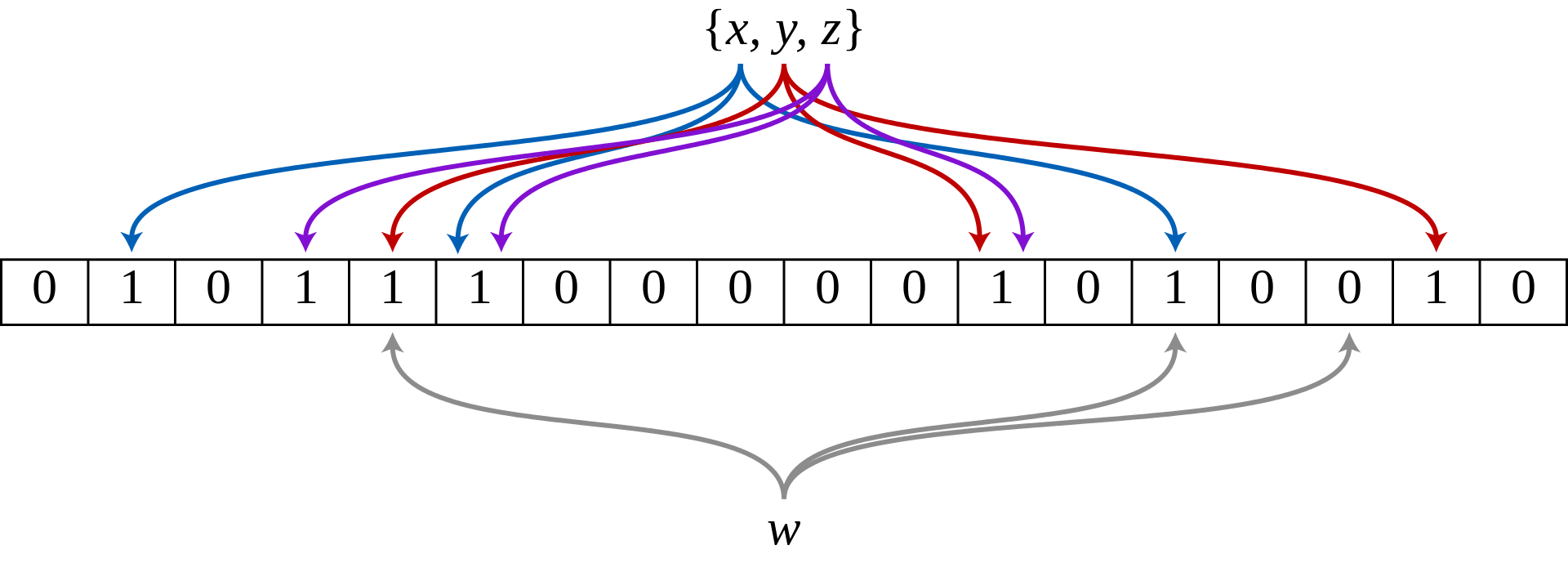
如图将集合中的x,y,z通过三个哈希函数得到的位数组上对应的位都设置为1。
判断元素是否在集合中
将需要判断的元素同样通过k个哈希函数得到k个对应的位数组上的位置,判断其位置上的位是否全为1,若是则元素可能存在在集合中,否则必定不存在。如上图的w通过哈希函数得到的位置上的位有一个不为1,则w必定不存在该集合中。
参数的选择
Bloom Filter主要有四个参数:
- $k$:哈希函数的个数
- $m$:位数组的大小
- $n$:集合的元素个数
- $p$:假阳性概率(false positive probability),即将不在集合中的元素判断为在集合中,误判的概率
哈希函数的数量$k$必须是正整数。如果不考虑这个约束,则对已给定的$m$和$n$或$p$,当$k$满足以下公式时误判的概率最小:
$$
k = -\frac{lnp}{ln2} = \frac{m}{n}ln2
$$
而由$n$和$p$可以得到最佳的$m$的值:
$$
m = -\frac{nlnp}{(ln2)^2}
$$
所以每个元素的最佳位数是:
$$
\frac{m}{n}=-\frac{lnp}{(ln2)^2}\approx-1.44log_2p
$$
实现
Bloom Filter的简单实现,参考:https://github.com/MagnusS/Java-BloomFilter
1 | import java.io.Serializable; |
应用
- 爬虫中的url去重
- Hbase中通过Bloom Filter来快速确定查询的数据是否在HFile中,加快查询速度