前言
Hadoop的搭建此次分为伪分布式和分布式,伪分布式分为windows和mac Os、Linux
伪分布式
Hadoop的伪分布式搭建需要提前安装好jdk1.8,选用hadoop3.0.0版本,官方提供的二进制和源码下载网址:https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/ ,此次的搭建使用二进制包安装,不涉及源码的编译,所以下载的文件为hadoop-3.0.0.tar.gz。
Windows
首先将下载好hadoop-3.0.0.tar.gz压缩包,解压到合适的目录下(目录位置用于配置环境变量,用户可以自行选择),为了接下来方便配置的讲解,假设本次例子解压目录为:E:\hadoop-3.0.0,后文的hadoop的xx目录都是该目录下的子目录。
windows启动脚本
在windows下安装hadoop,需要额外添加hadoop的window启动脚本,下载位置为:https://github.com/steveloughran/winutils ,选择相应的hadoop大版本,如本次安装为hadoop3.0.0。则需将winutils中hadoop-3.0.0\bin下的所有文件复制,粘贴到hadoop的bin目录下,即例子中的 E:\hadoop-3.0.0\bin中。
环境变量配置
修改hadoop-env.cmd文件
修改hadoop的etc\hadoop目录下hadoop-env.cmd文件,将文件中的set JAVA_HOME=%JAVA_HOME% 替换成 set JAVA_HOME=C:/Progra~1/Java/jdk1.8.0_144,用系统的JAVA_HOME的路径代替文件中JAVA_HOME的路径。
注意:本文只的jdk安装目录实际上为默认的C:/Program Files/Java/jdk1.8.0_144,但是该文件中参数的配置是不能出现空格的,如果含有空格,必须按照Windows 8.3 Pathname的路径规范书写,所以建议可以适当改变jdk的安装路径尽量不要包括空格等特殊符号。
添加环境变量
我的电脑 –> 属性 –> 高级系统设置中添加系统变量HADOOP_HOME,变量值为E:\hadoop-3.0.0,在path变量中添加%HADOOP_HOME%\bin; %HADOOP_HOME%\sbin;
Hadoop配置文件
修改hadoop的etc\hadoop目录下core-site.xml文件,添加以下配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 配置Hadoop临时目录文件 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///E:/hadoop-3.0.0/data/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///E:/hadoop-3.0.0/data/name</value>
</property>
</configuration>修改hadoop的etc\hadoop目录下hdfs-site.xml文件,添加以下配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<configuration>
<property>
<!-- hdfs的文件的默认副本数 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///E:/hadoop-3.0.0/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///E:/hadoop-3.0.0/data/dfs/datanode</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>修改hadoop的etc\hadoop目录下mapred-site.xml文件,添加以下配置
1
2
3
4
5
6
7<configuration>
<property>
<!-- mapreduce 运行在yarn上 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改hadoop的etc\hadoop目录下yarn-site.xml文件,添加以下配置
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
</configuration>
启动hadoop
第一次需要格式化hdfs,使用命令hadoop namenode -format
打开cmd,输入start-dfs和start-yarn命令分别启动hdfs和yarn。
访问http://localhost:8088 和http://localhost:9870 可以看到hdfs和yarn的web界面
运行wordcount
运行hadoop自带的wordcount例子,首先可以通过web界面向hdfs上传一个example.txt文件在新建的/input目录下,内容如下:
1 | A Grain of Sand |
运行wordcount的jar(在hadoop的share\hadoop\mapreduce目录下的hadoop-mapreduce-examples-3.0.0.jar)来统计本件中单词的数量
1 | E:\java\hadoop-3.0.0\share\hadoop\mapreduce>hadoop jar hadoop-mapreduce-examples-3.0.0.jar wordcount /input/example.txt /out |
最后可以看到hdfs上/out目录下part-r-00000的文件,内容为example文件的单词的统计
1 | A 1 |
Mac和Linux
下载解压安装包tar -zxvf hadoop-3.0.0.tar.gz。
环境变量配置
修改hadoop-env.cmd文件
修改hadoop的etc\hadoop目录下hadoop-env.cmd文件,将文件中的set JAVA_HOME=%JAVA_HOME% 替换成 set JAVA_HOME=,用系统的JAVA_HOME的路径代替文件中JAVA_HOME的路径。
添加环境变量
修改~/.bash_profile文件,在最后添加hadoop的环境变量
1
2
3vim ~/.bash_profile
export HADOOP_HOME=/Users/Cyan/coding/hadoop/hadoop-2.8.2
export PATH=$PATH:$HADOOP_HOME/bin
Hadoop配置文件
配置文件几乎和windows的一样,除了路径的书写,根据mac和linux的路径书写来
启动Hadoop和运行wordcount
和windows的一样,不重复了
遇到问题
针对mac,启动HDFS时,
start-dfs.sh,报错“connection refused”,则需要在计算机系统设置中打开远程登录许可。点击 Sharing(共享):
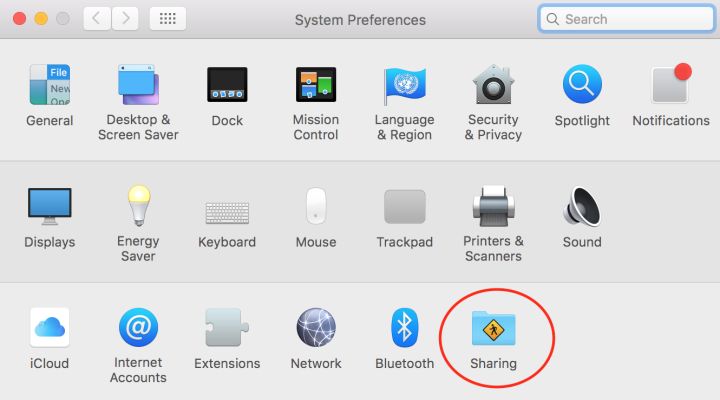
勾选 Remote Login(远程登录),然后添加当前用户:
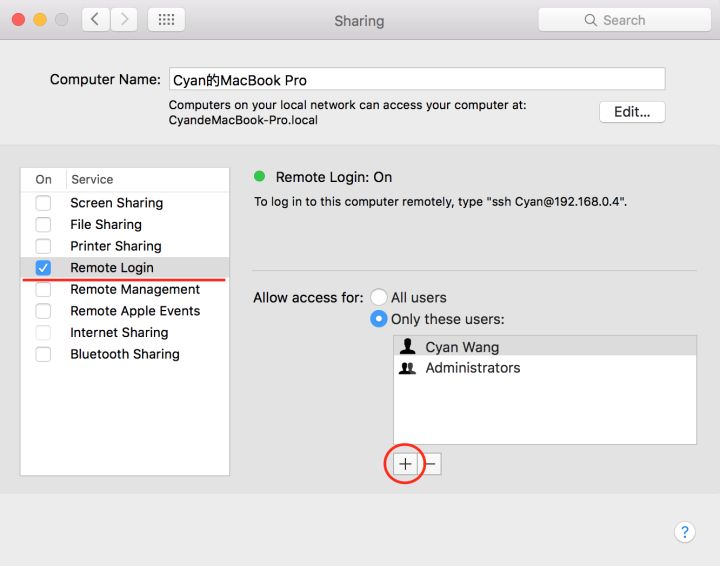
运行mapreduce程序。如wordcound,报错“错误:“找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster”
在yarn-site.xml中添加名为yarn.application.classpath的属性,值为hadoop classpath命令的输出结果
1
2hadoop classpath
/Users/zhongyue/hadoop-3.0.0/etc/hadoop:/Users/zhongyue/hadoop-3.0.0/share/hadoop/common/lib/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/common/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/hdfs:/Users/zhongyue/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/hdfs/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/mapreduce/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/yarn:/Users/zhongyue/hadoop-3.0.0/share/hadoop/yarn/lib/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/yarn/*1
2
3
4
5
6vim yarn-site.xml
<property>
<name>yarn.application.classpath</name>
<value>/Users/zhongyue/hadoop-3.0.0/etc/hadoop:/Users/zhongyue/hadoop-3.0.0/share/hadoop/common/lib/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/common/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/hdfs:/Users/zhongyue/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/hdfs/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/mapreduce/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/yarn:/Users/zhongyue/hadoop-3.0.0/share/hadoop/yarn/lib/*:/Users/zhongyue/hadoop-3.0.0/share/hadoop/yarn/*
</value>
</property>
分布式
hadoop分布式运行环境搭建是使用virtual Box创建三台Ubuntu虚拟机上进行的,所以会有一些ubuntu的一些配置,方便后续Hadoop的安装
更改apt源
由于apt原来的源太慢,改为国内阿里的源
1 | 备份原来的文件 |
固定IP地址
由于虚拟机使用的是桥接网络,固定ip方便以后ssh连接
首先查看虚拟机的网卡
1 | ip a |
可以看到这里的网卡编号为enp0s3,接下来编辑文件 sudo vi /etc/network/interfaces,写入静态ip地址(address),子网掩码(netmask)和网(gateway),配置固定的DNS,dns-nameserver后面接DNS服务器地址,可根据不同地域和网络网上查询得到,8.8.8.8万能的dns,修改sudo vim /etc/resolv.conf可以改变dns,但是重启失效。最后重启网络服务
1 | sudo vim /etc/network/interfaces |
ssh安装启动
1 | sudo apt-get install openssh-server |
将集群之间的公钥保存在authorized_keys中,形成集群机器之间的免密登陆
JDK配置
下载jdk文件,jdk-8u191-linux-x64.tar.gz
解压该文件到指定目录
1 | mkdir /usr/lib/Java |
接下来配置java的环境变量,在/etc/profile的最后添加环境变量
1 | vim /etc/profile |
最后查看是否配置成功
1 | java -version |
Hadoop安装
下载解压Hadoop 3.0的安装包
1 | wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz |
添加环境变量
修改/etc/profile,根据hadoop解压后的位置添加HADOOPCONF_DIR、HADOOP_HOME、HADOOP_HDFS_HOME,并将$HADOOP_HOME/bin和$HADOOP_HOME/sbin`追加入到path中,
1 | $ vim /etc/profile |
使修改的环境变量生效
1 | source /etc/profile |
修改host
集群域名和ip映射,方便之后配置
1 | cat /etc/hosts |
这里是三台机器组成集群,ip分别是10.1.16.111/112/113,对应域名hdp-1/hdp-2/hdp-3(分别是三台机器的hostname,也可以随意取名 ),这个需要按照实际ip和hostname 来
修改hadoop的配置文件
修改hadoop-env.sh
${HADOOP_HOME}/etc/hadoop/hadoop-env.sh,增加JAVA_HOME,同java环境变量中的相同
1 | export JAVA_HOME=/usr/lib/Java/jdk1.8.0_191 |
core-site.xml配置
${HADOOP_HOME}/etc/hadoop/core-site.xml配置hdfs中NameNode的URI(包括协议、主机名称、端口号),从上述选取一台作为namenode的节点
1 | <configuration> |
hdfs-site.xml配置
${HADOOP_HOME}/etc/hadoop/hdfs-site.xml,配置hafs中文件的备份数,以及namenode,datanode的存储位置,需要先创建namenode,datanode的存储位置,即下面的/data/hdp/namenode和/data/hdp/datanode
1 | <configuration> |
yarn-site.xml配置
${HADOOP_HOME}/etc/yarn-site.xml,配置resourcemanager运行的机器,为了能够运行MapReduce程序,需要让各个NodeManager在启动时加载shuffle server,接着是resourcemanager和jobhistory的UI界面的地址,开启日志聚集和保存时间
1 | <configuration> |
mapred-site.xml
${HADOOP_HOME}/etc/mapred-site.xml,配置mapreduce运行在yarn上
1 | <configuration> |
workers
${HADOOP_HOME}/etc/worker,将集群中的所有机器添加上去
1 | hdp-1 |
启动Hadoop
首次启动需要格式化namenode
1 | 格式化 |
可以通过jps查看启动了哪些组件
1 | hdp-1,由于namenode和resourcemanager在其上运行 |
通过配置的yarn.resourcemanager.webapp.address和mapreduce.jobhistory.webapp.address,可以看到yarn的信息界面,hdfs的信息界面默认在运行namenode机器的9870端口。
以上配置只是能让Hadoop够运行以及能看到基本信息,实际生产中还需要进行更多配置,有兴趣可以从官方查看各个配置参数。