表空间
InnoDB中数据都存放在一个空间中,就是表空间。在文件系统中就是idb文件,每个idb文件都是一个表空间。它们之间通过表空间id来区分,在默认情况下,InnoDB使用的是共享表空间,所有数据存放在一个共享表空间ibdata1中。共享表空间可以通过参数innodb_data_file_path进行配置。
可以同时配置多个文件组成一个共享表空间,如
1 | innodb_data_file_path=/data/ibdata1:2000M;/data/ibdata2:2000M:autoextend |
这里配置了/data/ibdata1和/data/ibdata2两个文件组成表空间,如果两个文件在不同磁盘上,能降低各个磁盘的负载,可以提高数据库的性能。同时,两个文件名后跟了存储大小,表示文件的最大存放空间,而autoextend表示/data/ibdata2若用完了2000M,文件可以自动增长。
实际上,除了共享表空间还有独立表空间,将参数innodb_file_pre_table设为ON可以开启独立表空空间。在独立表空间中,对于每张表内的数据都单独放在一个表空间中,但是每个表空间只会对应表的数据、索引和插入缓冲Bitmap页,其余数据,例如回滚日志,事务信息,二次缓存等还是存放在共享表空间。
表空间由段(segment)、区(extent)、页(page)组合。
数据页
页是InnoDB存储引擎管理数据库的最小磁盘单位。默认一个页的大小是16K,InnoDB 1.0.x后可以通过参数KEY_BLOCK_SIZE设置默认页大小为2K,4K,8K,InnoDB 1.2.x新增参数innodb_page_size可以设置默认页大小为4K,8K。
数据页由File Header、Page Header、Infimun和Supremum Records、User Records、Free Space、Page Directory、File Trailer组合。其中File Header、Page Header和File Trailer的大小是固定的,分别占用38、56、8个字节,记录数据页的信息。而Infimun、Supremum Records、User Records、Free Space、Page Directory存储的信息和实际的行数据有关,因此大小是动态的。
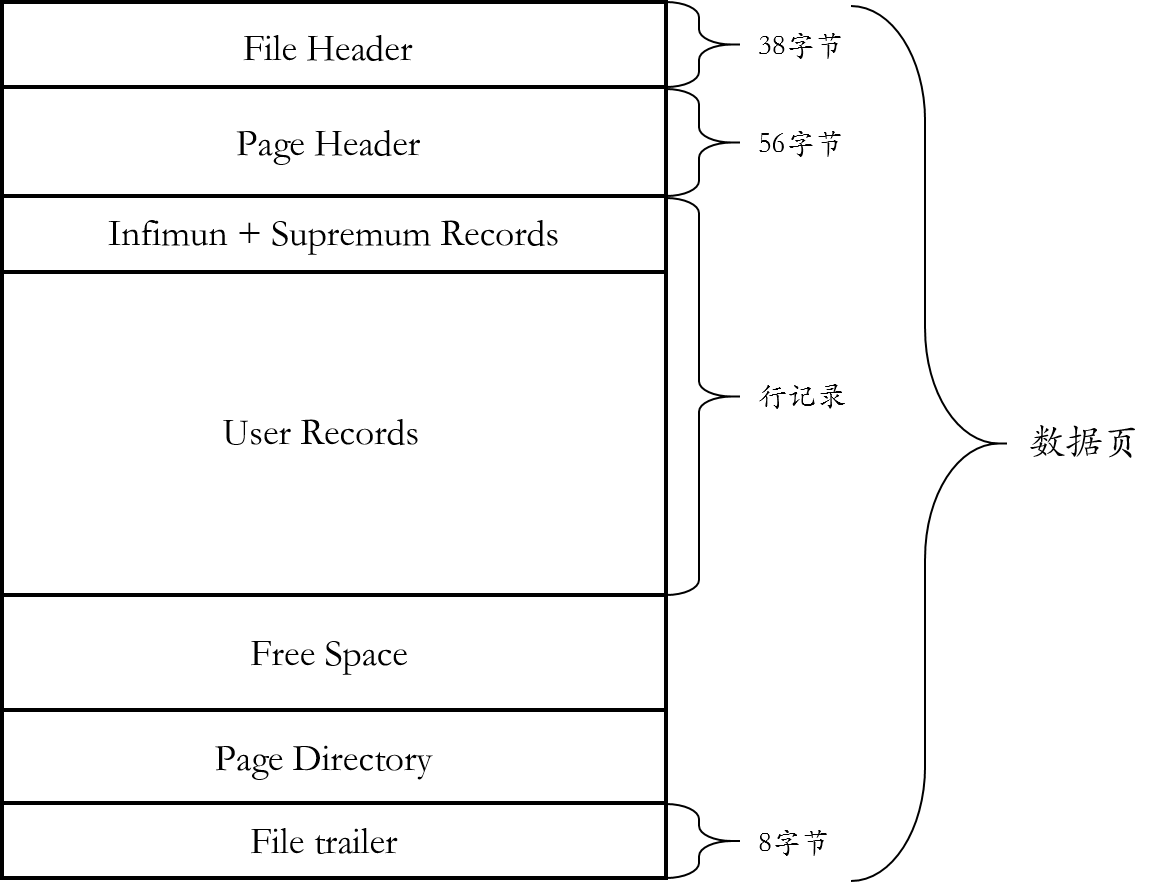
File Header
File Header固定38个字节,用来记录页的头信息。
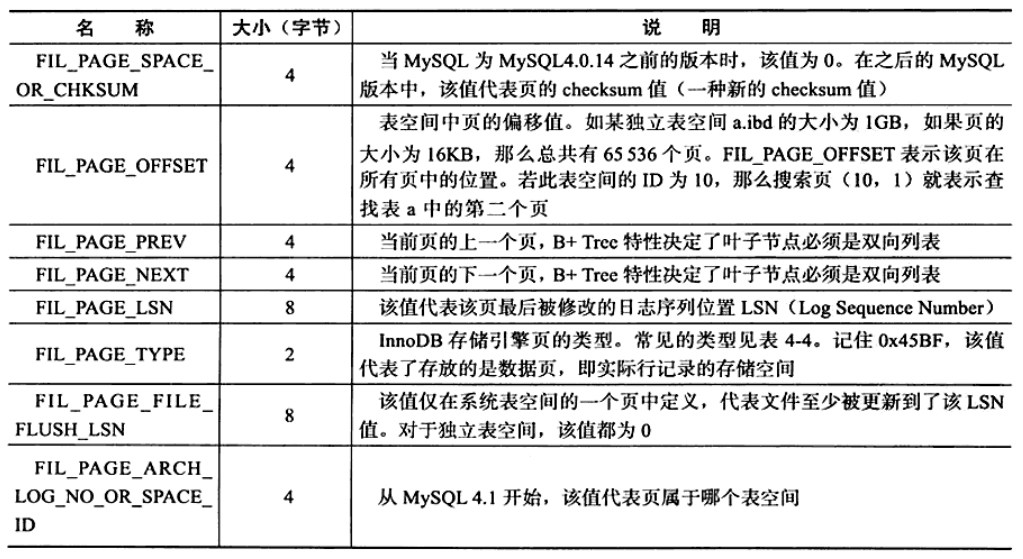
File Header中的FIL_PAGE_PREV和FIL_PAGE_NEXT分别是记录了上一页和下一页在表空间中的位置,因此页与页之间是通过链表的数据结构连接再一起,而且是一个双向链表。
Page Header
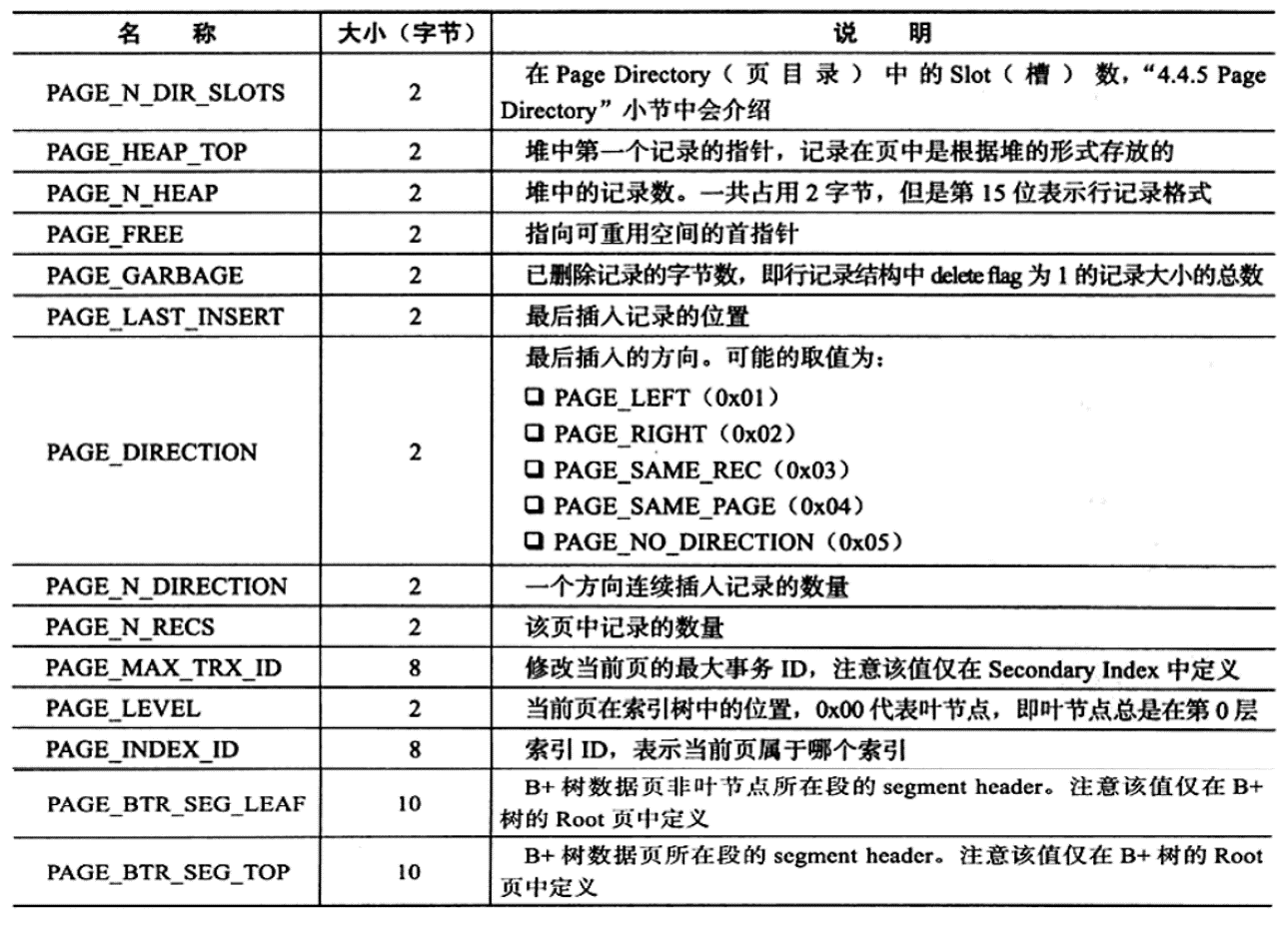
Page Header接着File Header之后,固定56字节,记录数据页的状态信息。
Infimun和Supremum Records
Infimun和Supremum Records是虚拟的两个行记录,用来限定实际数据行的边界。Infimun是比页中任何主键值都小的值,而Supremum是比任何主键值都要大的值。这两值在页被创建时就被建立,不会被删除。
User Records
存储实际行记录的内容。数据库中一行数据对应文件中的一行记录格式。目前InnoDB只要有两种行记录格式:Compact和Redundant,Compacts是mysql 5.1之后的默认行记录格式,Redundant是为了兼容之前的版本而保留。接下来分别介绍这两种行记录格式。
Compact行记录格式
Compact行记录格式能够高效的存储行记录,一页中存放的行数据越大,性能就越高。Compact的存储格式如下图:

变成字段长度列表记录了行记录中变长字段(varchar)的长度,其按照列的顺序逆序放置,一个变长字段的长度最大不会超过2个字节,因为varchar类型的最大长度为65535,正好是2的16次方,因此最多两个字节就能记录下该字段的长度。如果该列的长度小于255字节,则用1个字节表示,如果大于255字节,则用2个字节表示。
例如,创建一张表z,包括三个变长字段,一个固定长度字段,则其对对应的变长字段列表如下
1 | CREATE TABLE test( |
第一行对应的变长字段长度列表为04 03 01(dddd,ccc,a),第二行04 02 01(gggg,ff,e),第三行为04 01(gggg,e),因为t3为固定长度字段,所以不会记录其长度,对已NULL的字段也是不会记录,比如第三行的t2字段。
NULL标志占1个字节,表示该行记录有无NULL值,有则为1,无为0。字段中的NULL值实际上不记录在compact格式中,所以NULL数据实际上除了占有NULL标志位以外不占用任何存储空间。
记录头信息固定占5个字节,详细表示记录的信息如下图
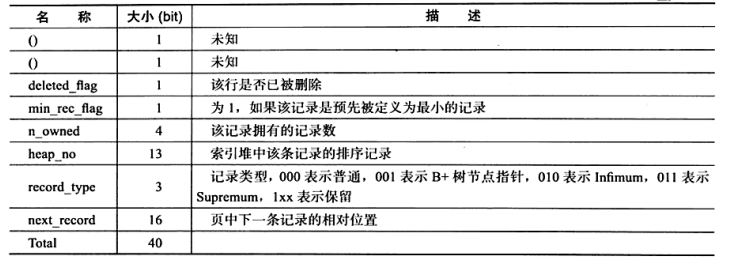
从行记录头中的next_record可以看出行与行之间同样是链表的方式存储,因此一页之间的行与行其实不需要按照顺序存储,实际上行存储顺序可能是无序的,但是通过链表将其按照主键顺序串连在一起。n_owned是和下文要讲的Page Dirextory有关,帮助在页中查找行记录。
接下来分别是事务ID和回滚指针,分别占用6字节和7字节,如果InnoDB表没有指定主键也没有非空唯一索引,则会在事务ID前增加一个自动创建的6字节的主键ID。
最后存储的就是各个字段上实际数据。
Redundant行记录格式
Redundant行记录格式是为了兼容之前版本的页格式,其存储格式如下:

地段长度偏移列表表示各个字段(包括主键ID,事务ID,回滚指针,列数据,不包括记录头信息)距离记录头信息开始的偏移量。
redundant记录头信息占6个字节,格式如下:
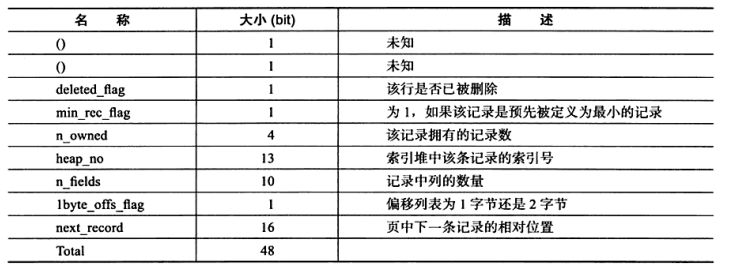
接下来的信息格式和Compact行记录格式一样,除了对NULL值的处理,在Compact中除了NULL标志外实际上是不存储NULL值,但是redundant中NULL是记录其内容,具体内容就是用00填充其固定字段长度,对于变长字段则同样不占用任何存储空间,即不记录变长字段NULL值。
Free Space
Free Space指的是页中的空闲空间,同样是链表的数据结构,当一行被删除之后,该空间就会被加入Free Space当中。
Page Directory
Page Directory也叫页目录,存放的是记录在页中的相对位置。这些记录指针被称为slots(槽)。InnoDB的页中的并不是为每一条记录存放在槽,InnoDB实际上采用的是稀疏目录,即一个槽中可能存放的是多个记录。slots中的记录是按照主键索引值逆序排放的,每个槽占两个字节,通过槽中的指针找到对应行记录的位置,行记录头中的n_owned记录了该记录拥有的记录数,即槽中存放的记录数。
slots中的记录是按照主键索引值逆序排放的,通过槽使用二分查找可以快速的找到页中相应行记录的位置。例如,页中记录的主键值有{g, i, c, k, e, f, a, h, b, j, l, d},假设一个槽存放4条记录,则按照主键排序的逆序,槽中的记录可能是{a, e, i}
通过槽使用二分查找查找到的结果只是一个粗略的结果,需要获得准确的结果,还需通过next_record顺着链表最多查看n_owned条记录是否符合要求。
实际上通过InnoDB查找记录的顺序是首先通过B+书找到相应的页,接着将页加载到内存中,在页中通过Page Directory利用二分查找找到粗略的位置,最后通过链表找到记录。只不过在内存中二分查找的过程很快,一般忽略这部分的查找时间。
File Trailer
File Trailer是为了检测页是否完整的写入磁盘而设置的,其中包含checksum值,通过相应的checknum函数进行比较,检测页的完整性。
InnoDB数据页与索引
聚簇索引
InnoDB针对每张表的主键都会构造一颗B+树,即聚簇索引(Clusterd Index),所以InnoDB的每张表都有聚簇索引,就是其在主键上创建的索引。索引结构同B+树的数据结构相同,但与辅助索引不同的是其叶子节点存放的是所有的数据,即聚簇索引叶子节点实际上就是数据页,叶子节点之间通过双向链表有序的连接在一起,即上文每个数据页的File Header都有FIL_PAGE_PREV和FIL_PAGE_NEXT记录上一页和下一页的位置。聚簇索引在物理存储上并不是按照顺序的存放,而是通过其双向链表和数据页中的行记录格式的行链表实现了逻辑上的顺序存放,沿着链表查看是顺序存放的。
因此通过聚簇索引查找实际上分三种查找方式:
- 根据B+树查找到对应的数据页
- 在数据页中根据Page Directory的稀疏目录找到粗略的行记录位置
- z最后根据next_record在链表上顺序查找
辅助索引
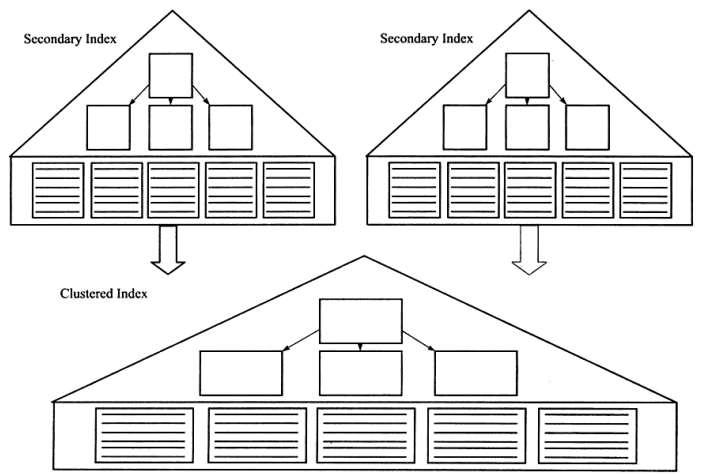
在InnoDB表的非主键字段上建立的B+树索引也称为辅助索引(Secondary Index)。辅助索引结构同样是B+树的结构,但是其叶子节点存放的不是数据页,而是索引的键值加上主键值。
通过辅助索引可以查找到相应的主键值,接着利用主键值在聚簇索引上找到实际数据,即我们通过辅助索引查找实际上是通过两颗B+树查找。
与非聚簇索引的比较
例如MYISAM存储引擎使用的是非聚簇索引,不同于聚簇索引的是其叶子节点存放的是数据存放的地址。其主索引和辅助索引除了键值不同外并没有什么区别,叶子节点都是使用指针指向真正的数据地址。
对于离散的查找,聚簇索引要比非聚簇索引慢一些,因为聚簇索引要走两颗B+树的I/O。
在数据的更新上,特别是更新影响到物理地址的变化,聚簇索引要比非聚簇索引,因为非聚簇索引需要改变所有索引上相应叶子节点的物理地址,而聚簇索引叶子节点直接存放数据,辅助索引存放的是主键值,无需改变。
- 对于排序和范围查找,聚簇索引将数据按照逻辑顺序排列,能够通过一行记录的位置快速找到其相应的周围的记录,明显比非聚簇索引好。