前言
MapReduce作为Hadoop三大核心组件之一,是一种处理大数据的分布式运算框架。虽然当前优秀的分布式运算框架有很多,如spark,flink等,其有着MapReduce没有的流式处理模型,但是MapReduce在批量计算有着独有的优势,了解其内部的运行机制,对于大数据处理技术人员和学习人员都着重要的意义。
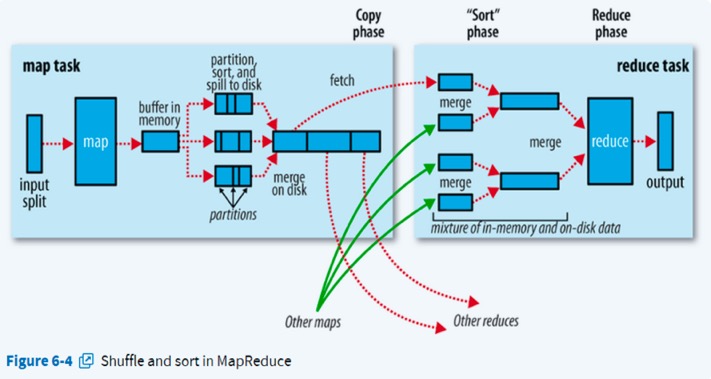
MapReduce从其名字上可以看出,有Map和Reduce两个步骤,确实在MapReduce中分map端和reduce端,而连接着map端和reduce端的操作就是shuffle。接下来将详细介绍map端和reduce端以及shuffle,来了解Mapreduce是如何处理数据。(其中将不和涉及到Mapreduce任务是如何提交,启动,如何分配资源执行MapReduce任务,因为在hadoop2.0之后引入了资源调度框架yarn,这些事情已经全部都交yarn,MapReduce作业运行机制将在yarn中讲解。这里只讲MapReduce如何处理数据)。可以看到其过程的官方描述图如下
文件输入
文件的切分
MapReduce的输入文件,即处理数据,一般是存储在HDFS上,在将其输入到Map进行处理之前,会有一步文件切分的动作,将文件切分成多片(split),这将决定map的数量。因为一个MapReduce的任务会有很多个map,map的数量并不是由集群由多少台机器或者机器的配置决定的,而是由输入分片split的数量决定,一个split由一个map来处理,每一个map操作只处理一个输入分片。默认的split大小就是HDFS的block大小,也就是默认情况下,文件在HDFS上占多少个block,对其用MapReduce处理时就有多少个map。
用户可以通过调整分片大小来改变分片的数量,从而决定map的数量。分片大小的计算方式,可以在FileInputFormat的computeSplitSize()方法中看到:
max(minsize, min(maxsize, blockSize))
式子里的参数分别由三个配置参数设置:
| 参数 | 配置参数 | 类型 | 默认值 |
|---|---|---|---|
| minsize | mapreduce.input.fileinputformat.split.minsize | int | 1 |
| maxsize | mapreduce.input.fileinputformat.split.maxsize | long | Long.MAX_VALUE |
| blockSize | dfs.blocksize | Long | 128M |
文件的切分并不是实际上把文件拆成一个个小文件,而是split其实就是记录文件块所在的host位置及其起始和末尾偏移量。
host选择
文件切分之后,为了避免文件和map在不同机器上需要通过网络传输文件,需要选择合适的host,因为map在执行时会尽量选择本地的split数据处理,因此选择合适的host尤其重要。
但是由于split可能不会等于block的大小,一个split可能会分布在不同的block上,所以无法完全做到map处理本地数据。
host选择的原则是优先让空闲资源处理本节点上的数据,如果节点上没有可处理的数据,则处理同一个机柜上的数据,最坏的情况是处理其他机柜上的数据(当然必须在同一数据中心)。
host选择算法具体可以看:
https://blog.csdn.net/xingliang_li/article/details/53285447
《Hadoop技术内幕-深入解析MapReduce架构设计与实现原理》
Map端
Map端根据输入的数据和用户定制的map函数处理数据,默认采用TextInputFormat,按行记录迭代调用map函数。经map函数处理完的数据(通过context.write(key,value)输出)会经过partition方法产生一个对应到reduced的分区号,将<key,value,numPartitions>输出到一个环形缓冲区中。
Partition
Partition的作用是对map的输出结果计算一个分区号,标记输出数据应该对应到哪一个Reduce来处理。默认的Partiton是HashPartition,对map输出的key取hash值,再对reduce的数量取模。
Partition方法可以通过Job.setPartitionerClass(Class<? extends Partitioner> cls)的方法设定自定义的Partition类,继承Partitioner类,覆盖getPartition方法即可。
环形缓冲区(也是内存缓冲区)
环形缓冲区的默认大小为100M,可以通过参数mapreduce.task.io.sort.mb来调整其大小,当缓冲区中被放入数据达到一定的阈值(默认为缓冲区大小的80%,通过mapreduce.map.sort.spill.precent设置)就会启动一个后台线程将内容溢写spill到磁盘中。在spill到磁盘的过程中,map的输出还会持续的写入的缓冲区中,如果此时map写入过快,spill还未完成,缓冲区已经满了,就会发生阻塞知道spill完成。
spill
spill是当环形缓冲区中数据到达阈值时,写入到磁盘的过程。在写入磁盘之前,需要按照分区号numPartition对数据进行分组,每一组的分区号相同,对于每一组的中的数据按照key值进行排序,这次排序采用的快速排序,因此spill到磁盘的数据应该是分好组,按照组排下来,每一组中的元素是按照key排序好的。
每次spill就会产生一个分组排序好的spill文件,这样一次map可能会产生多个spill文件,但是最后一个map的输出之后产生一个文件,因此在map结束之后需要对所有的spill文件进行一次merge。
merge
将一个map从环形缓冲区spill到磁盘中,一个map可能产生多个spill文件,需要经过merge产生一个文件。考虑到分区号是数据交给哪个reduce的凭证,因此merge之后的单个文件也是分组排序好的,组中的元素分区号相同,并且按照key排序。因此merge是按照分区号对多个文件按照归并排序进行排序,归并一个能合并多个文件,最多合并的文件个数默认是10个,由配置参数mapreduce.task.io.sort.factor控制。
Combine
如果设置过Combine,combine的触发主要发生在两个地方:
- spill按照分区号分组排序号之后,将要写入到磁盘之前会触发一次combine
- 如果至少存在3个spill文件(通过mapreduce.map.combine.minspills设置),则会在marge的过程中触发combine
combine的数据处理方法和reduce相同,对key值相同的数据调用combie方法,combine可以提前合并一部分数据,减少数据的产生传输,为reduce处理减轻压力。
Reducd端
拉取合并
map产生的输出的文件存储于运行map任务的tasttracker的本地磁盘中(hdfs中),reduce需要启动线程通过HTTP方式从map的输出文件中按照reduce对于的分区号复制数据,默认是5个线程(通过mapreduce.reduce.shuffle.parallelcopies设置),不需要等到map全部完成才启动复制线程,默认map完成数大于map任务总数的5%时即可开始启动复制线程,从已经完成的map任务输出的文件复制数据。复制的数据同样是放入缓冲区中。
内存缓冲区
reduce端的内存缓冲区不像map端的内存缓冲区,没有固定的大小,其大小与reduce任务的jvm的最大heap的大小有关(通常通过mapred.child.java.opts来设置,比如设置为-Xmx1024m),默认其大小为最大heap的70%(通过mapreduce.reduce.shuffle.input.buffer.percent设置),所以缓冲区大小等于maxHeap of reduce * precent。
一旦缓冲区达到了阈值(通过mapreduce.reduce.shuffle.merge.precent设置)或者map输出的阈值(通过mapreduce.reduce.merge.inmem.threshold设置)就会发生spill,将数据写入磁盘。
merge
由于存在多个map端的输出数据,因此需要将其merge成一个reduce输入,这里的merge指的就是合并多个map的输出。其主要发生在两个地方,当缓冲区达到阈值需要spill时,这个spill中需要merge,merge按照归并排序将多个map端的数据排序好输出到磁盘,如果有combine,combine会在写入到磁盘前触发。随着磁盘上文件增大,后台会启动线程将多个spill文件合并成更大,排序好的文件。当所有的map输出都传输完毕,就需要将所有的spill文件merge合并成一份reduce输入,和map相同,采用多路归并排序,在发生最后一次归并排序时是不落盘,直接将其结果输入到reduce中,减少一次落盘操作。
最后就是将输入给reduce,reduce的输出直接落盘到HDFS中结束。
shuffle
上述过程只有Map端和Reduce端,为什么没有Shuffle,其实Shuffle就是执行map方法输出数据到reduce方法输入数据这中间的一系列过程,包括map端的spill、merge,Reduce端的拉取合并、merge等,Shuffle实际上是与Map和Reduce的过程交叉存在的。
参考
《Hadoop权威指南》